[모던 자바 인 액션] 08. 컬렉션 API 개선
Reference
📌 컬렉션 팩토리
Java 9에서는 작은 컬렉션 객체를 만들 수 있는 몇 가지 방법을 제공한다. 이 중 팩토리 메서드는 데이터가 변경될 필요가 없는 작은 크기의 리스트, 집합, 맵을 쉽고 간단하게 만들 수 있도록 도와준다.
먼저 add() 메서드를 통해 요소를 추가하는 형식으로 컬렉션을 만든다고 가정한다
List<String> friends = new ArrayList<>();
friends.add("A");
friends.add("B");
friends.add("C");
세 개의 요소를 추가하는데 비교적 많은 코드가 필요하다
여기서 Arrays.asList() 팩토리 메서드를 이용하면 코드를 간단하게 줄일 수 있다
List<String> friends = Arrays.asList("A", "B", "C");
Arrays.asList()는 고정 크기의 리스트를 생성해 요소를 갱신할 수 있지만 새 요소를 추가하거나 삭제할 수 없다. 만약 요소를 추가 하면 UnsupportedOperationException이 발생한다.
List<String> friends = Arrays.asList("A", "B", "C");
try {
friends.set(0, "a");
friends.add("D"); // ERROR
} catch (UnsupportedOperationException e) {
System.out.println("friends = " + friends);
e.printStackTrace();
}

실행된 결과를 보면 리스트 요소의 갱신은 성공적으로 일어났지만 요소를 추가하는 부분에서 예외가 발생한다.
내부적으로 고정된 크기의 변환할 수 있는 배열로 구현되었기 때문에 요소를 추가하면 예외가 발생한다.
그렇다면 Set은 어떨까? Set은 Arrays.asSet() 팩토리 메서드가 없어 다른 방법이 필요하다. 리스트를 인수로 받는 HashSet 생성자를 사용하거나 스트림 API를 사용할 수 있다.
Set<String> friendsSet = new HashSet<>(Arrays.asList("A", "B", "C"));
Set<String> friendsStream = Stream.of("A", "B", "C").collect(Collectors.toSet());
위 두 방법 모두 내부적으로 불필요한 객체 할당을 필요로 한다. 그리고 생성된 Set은 변환(갱신)할 수 있는 Set이라는 사실에 주목해야 한다.
Map도 작은 Map를 만들 수 있는 방법이 없었지만 Java 9부터 작은 리스트, Set, Map을 쉽게 만들 수 있는 팩토리 메서드를 제공한다.
컬렉션 리터럴(Collection Literal)
Python, Groovy 등 일부 언어는 컬렉션 리터럴인 [1, 2, 3] 같은 특별한 문법을 이용해 컬렉션을 만들 수 있는 기능을 지원한다. Java는 언어는 변화와 관련된 비용이 큰 이유로 컬렉션 리터럴 기능을 지원하지 못했고 대신 컬렉션 API를 개선했다
리스트 팩토리(List Factory)
List.of() 팩토리 메서드를 이용하면 간단하게 리스트를 만들 수 있다. 하지만 생성된 리스트에 요소를 추가하면 UnsupportedOperationException이 발생한다.
List<String> friends = List.of("A", "B", "C");
friends.add("D"); // ERROR
List.of()는 변경할 수 없는 리스트를 만들기 때문에 UnsupportedOperationException이 발생한다.

List.of()로 생성된 리스트는 의도치 않게 변하는 것을 막고 null 요소를 금지해 버그를 방지하고 간결한 내부 구현을 달성한 장점이 있다.
하지만 리스트를 바꿔야 하는 상황이 오면 직접 리스트를 만들어 새로운 리스트로 대체해야 한다.
데이터 처리 형식을 설정하거나 데이터를 변환할 필요가 없다면 팩토리 메서드를 이용할 것을 권장한다.
오버로딩 vs 가변 인수
List 인터페이스를 보면
List.of()는 다양한 오버로드 버전이 있다는 것을 확인할 수 있다.of(E... elements)처럼 가변 인수를 사용해 다중 요소를 받을 수 있는데 왜 다양한 오버로딩을 선택한 것일까?그 답은 타입 안정성(Type Safety)과 좋은 성능을 제공하기 위해서다. 내부적으로 가변 인수는 추가 배열을 할당해서 리스트로 감싼다. 따라서 배열을 할당하고 초기화하며 나중에 GC 비용을 지불해야 한다. 다양한 오버로딩(요소 1개 ~10개)을 통해 이런 비용을 제거할 수 있다.
하지만
List.of()로 생성할 리스트의 요소가 10개가 넘어가면 가변 인수를 통해 생성한다. 그러니 작은 크기의 리스트를 만들 때 데이터를 변경할 일이 없다면 팩토리 메서드를 쓰는 것이 좋다. Map과 Set의 of도 List.of와 같은 패턴으로 구현되었다.
집합 팩토리(Set Factory)
Set도 List와 마찬가지로 Set.of()를 통해 바꿀 수 없는 Set을 만들 수 있다. 마찬가지로 요소를 추가하면 UnsupportedOperationException이 발생한다.
중복된 요소를 제공해 Set을 만들면 요소가 중복되어 있다는 설명과 함께 IllegalArgumentException이 발생한다.
Set<String> friends = Set.of("A", "B", "C");
friends.add("D"); // UnsupportedOperationException
Set<Integer> numbers = Set.of(1, 2, 3, 3); // IllegalArgumentException
맵 팩토리(Map Factory)
Java 9에서는 두 가지 방법으로 바꿀 수 없는 맵을 생성할 수 있다
Map.of()팩토리 메서드: 10개 이하의 키와 값 쌍을 가진 작은 Map을 만들 때 사용
Map<String, Integer> ageOfFriends = Map.of("A", 20, "B", 21, "C", 22);
-
Map.ofEntries()팩토리 메서드: 10개를 초과한 키와 값 쌍을 가진 Map을 만들 때 사용-
가변 인자를 사용한 메서드
-
Map.entry를 통한 객체 할당을 필요로 한다
-
import static java.util.Map.entry;
Map<String, Integer> ageOfFriends =
Map.ofEntries(entry("A", 20), entry("B", 21), entry("C", 22));
📌 리스트와 집합 처리
Java 8은 List, Set 인터페이스에 다음 메서드를 추가했다
removeIf(): Predicate를 만족하는 요소를 제거- List or Set을 구현하거나 그 구현을 상속받은 모든 클래스에서 사용 가능
- Predicate: 입력 값을 받아서 논리적 조건을 검사
replaceAll(): UnaryOperator 함수를 이용해 요소를 바꿈- List에서 사용할 수 있는 기능
- UnaryOperator: 입력으로 하나의 값을 받아서 같은 타입의 값을 반환, 단항 연산을 수행
sort(): List를 정렬- List에서 사용할 수 있는 기능
위 세개의 메서드는 호출한 컬렉션 자체를 변경한다. 새로운 결과를 만드는 스트림 동작과 달리 이들 메서드는 기존 컬렉션을 변경한다.
컬렉션을 변경하는 동작은 에러를 유발하고 복잡함을 더하는데 이런 메서드가 추가된 이유는 무엇일까? 개발자가 직접 컬렉션을 변경하는 코드를 작성하면 버그가 발생하거나 원하는 동작과 다른 결과가 나올 수 있어 Java 에서 쉽고 버그를 일으키지 않는 메서드를 통해 컬렉션 변경을 제공한다.
removeIf()
숫자로 시작되는 참조 코드를 가진 트랜잭션을 삭제하는 코드가 있다
for (Transaction transaction : transactions) {
if (Character.isDigit(transaction.getReferenceCode().charAt(0))) {
transactions.remove(transaction);
}
}
위 예제 코드는 ConcurrentModificationException을 일으킨다. 그 이유는 for-each 루프는 내부적으로 Iterator 객체를 사용하기 때문이다. 이를 코드로 보면 다음과 같다
for (Iterator<Transaction> iterator = transactions.iterator();
iterator.hasNext(); ) {
Transaction transaction = iterator.next();
if (Character.isDigit(transaction.getReferenceCode().charAt(0))) {
transactions.remove(transaction); // 반복하면서 별도의 두 객체를 통해 컬렉션을 바꿈
}
}
ConcurrentModificationException: 한 스레드가 컬렉션을 수정하는 동안 다른 스레드가 컬렉션을 순회하고 있을 때 발생하는 예외. 동기화를 보장하지 않는 컬렉션에 대해 동시에 수정 및 순회를 시도할 때 발생
이 상황에서 두 개의 개별 객체가 컬렉션을 관리하게 된다.
- Iterator 객체: next(), hasNext()를 통해 소스를 질의
- Collection 객체: 자체 remove()를 호출해 요소를 삭제
결과적으로 Iterator 객체의 상태는 컬렉션의 상태와 서로 동기화되지 않는다. 이 문제를 해결하기 위해서는 Iterator 객체를 명시적으로 사용하고 그 객체의 remove() 메서드를 호출해 해결할 수 있다.
for (Iterator<Transaction> iterator = transactions.iterator();
iterator.hasNext(); ) {
Transaction transaction = iterator.next();
if (Character.isDigit(transaction.getReferenceCode().charAt(0))) {
iterator.remove();
}
}
위 코드는 처음 코드보다 복잡해졌지만 에러가 발생하지 않는다. 여기서 Java 8에서 제공하는 removeIf()를 이용하면 코드가 단순해지고 버그도 예방할 수 있다.
removeIf()는 삭제할 요소를 가리키는 Predicate를 인수로 받는다
transactions.removeIf(transaction ->
Character.isDigit(transaction.getReferenceCode().charAt(0))
);
replaceAll()
때로는 요소를 제거하는게 아니라 바꿔야 하는 상황이 존재하는데, 이럴 때 사용하는 메서드가 replaceAll()이다
List 인터페이스의 replaceAll()은 리스트의 각 요소를 새로운 요소로 바꾸는 기능을 제공한다. 참조 코드들의 첫 문자를 소문자에서 대문자로 바꾸는(변경하는) 기능을 스트림 API를 사용하면 다음과 같다
referenceCodes.stream()
.map(code -> Character.toUpperCase(code.charAt(0)) + code.substring(1))
.collect(Collectors.toList());
이 코드는 새 문자열 컬렉션을 만든다. 기존 컬렉션을 바꾸는(변경하는) 것을 원했지만 스트림 API를 사용하면 기존 컬렉션을 완전히 새로운 컬렉션으로 대체한다.
ListIterator 반복자 객체를 이용하면 코드가 복잡해지지만 기존 컬렉션을 바꾸는것이 가능하다.
for (ListIterator<String> iterator = referenceCodes.listIterator();
iterator.hasNext(); ) {
String code = iterator.next();
iterator.set(Character.toUppercase(code.charAt(0)) + code.substring(1));
}
하지만 컬렉션 객체를 Iterator 객체와 혼용하면 반복과 컬렉션 변경이 동시에 이루어지면서 쉽게 문제를 일으킨다. 그래서 Java 8의 replaceAll()을 사용하면 간단하고 버그를 일으키지 않는 코드를 구현할 수 있다.
replaceAll()은 UnaryOperator 함수를 이용해 기존 컬렉션의 요소를 바꾼다(변경)
referenceCodes.replaceAll(code ->
Character.toUppercase(code.charAt(0)) + code.substring(1)
);
📌 Map 처리
Java 8에서는 Map 인터페이스에 몇 가지 디폴트 메서드(default method)를 추가했다. 자주 사용되는 패턴을 구현할 필요가 없도록 이들 메서드를 추가한 것이다.
forEach 메서드
Map에서 키와 값을 반복하는 작업은 귀찮은 작업 중 하나이다. 기존에는 Map.Entry<K, V>의 반복자를 이용해 항목 집합을 반복했다.
for (Map.Entry<String, Integer> entry: ageOfFriends.entrySet()) {
String friend = entry.getKey();
Integer age = entry.getValue();
System.out.println("name = " + friend, ", age = " + age);
}
Java 8은 BiConsumer를 인수로 받는 forEach 메서드를 지원해 조금 더 간편하게 구현할 수 있게 만들었다
- BiConsumer: 두 개의 인자를 받아들이고, 리턴값이 없는(즉, void를 반환하는) 메서드를 정의하는데 사용
- 여기서는 Key와 Value를 인자로 받음
- 두 개의 인자를 소비해 원하는 작업을 수행
ageOfFriends.forEach((friend, age)
-> System.out.println("name = " + friend, ", age = " + age));
정렬 메서드
다음 두 개의 유틸리티를 이용하면 맵의 항목을 Key 또는 Value를 기준으로 정렬할 수 있다
Entry.comparingByValueEntry.comparingByKey
import static java.util.Map.entry;
import java.util.Map;
import java.util.Map.Entry;
public class MapSortExample {
public static void main(String[] args) {
Map<String, String> favoriteMovies = Map.ofEntries(
entry("C", "Avatar"),
entry("B", "God Father"),
entry("A", "Star Wars")
);
favoriteMovies.entrySet()
.stream()
.sorted(Entry.comparingByValue()) // 영화 이름을 알파벳 순으로 스트림 요소를 처리
.forEachOrdered(System.out::println);
}
}

HashMap 성능
Java 8은 HashMap의 내부 구조를 바꿔 성능을 개선했다. 기존 Map의 항목은 키로 생성한 해시코드로 접근할 수 있는 bucket에 저장했다. 많은 키가 같은 해시코드를 반환하는 상황이 되면 O(n) 시간이 걸리는 LinkedList로 bucket을 반환해야 하므로 성능이 저하된다.
Java 8은 bucket이 너무 커지면 O(log(n))의 시간이 소요되는 정렬된 트리를 이용해 동적으로 치환해 충돌이 일어나는 요소 반환 성능을 개선했다. 하지만 Key가 String, Number 클래스 같은 Comparable 형태여야만 정렬된 트리가 지원된다
getOrDefault 메서드
요청한 Key가 맵에 존재하지 않을 때 어떻게 처리하느냐도 흔히 발생하는 문제다.
기존에 찾으려는 키가 존재하지 않으면 null이 반환되어 NullPointerException을 방지하려면 요청 결과가 null인지 먼저 확인해야 한다. 이때 기본값을 반환하는 형식으로 이 문제를 해결할 수 있다
getOrDefault(Object key, V defaultValue): 첫 번째 인자로 Key, 두 번째 인자로 기본 값을 받아 맵에 key가 존재하지 않으면 인자로 받은 기본값을 반환
import static java.util.Map.entry;
import java.util.Map;
public class MapDefaultValueExample {
public static void main(String[] args) {
Map<String, String> favoriteMovies = Map.ofEntries(
entry("C", "Avatar"),
entry("B", "God Father"),
entry("A", "Star Wars")
);
System.out.println(favoriteMovies.getOrDefault("A", "좋아하는 영화 없음"));
System.out.println(favoriteMovies.getOrDefault("D", "좋아하는 영화 없음")); // key 없음
}
}

Key가 존재해도 값이 null인 상황에서는 getOrDefault()가 null을 반환할 수 있다. 즉, Key의 존재여부에 따라서 두 번째 인수인 기본값이 반환될지 결정된다.
계산 패턴
맵에 Key가 존재하는지 여부에 따라 어떤 동작을 실행하고 결과를 저장해야 하는 상황이 필요할 때가 있다. 예를 들어 Key를 이용해 값비싼 동작을 실행해서 얻은 결과를 캐싱하려 할때, Key가 존재하면 결과를 다시 계산할 필요가 없다. 다음 세 가지 연산이 이런 상황에 도움을 준다
세 메서드의 반환 타입은 V 로 제공된 key에 대응하는 값을 반환한다
-
computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)- 제공된 Key에 해당하는 값이 없으면(값이 없거나 null), Key를 이용해 새 값을 계산하고 맵에 추가
- 이미 해당 Key에 값이 존재하면 아무런 작업도 수행하지 않음
favoriteMovies.computeIfAbsent("B", value -> "Avengers");
-
computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction)- 제공된 Key가 존재하면 새 값을 계산하고 맵에 추가
- 제공된 Key의 값이 null 이면 아무런 작업을 수행하지 않고 null을 반환
- 제공된 Key가 존재하지 않으면 아무런 작업도 수행하지 않고 기존 값을 반환
favoriteMovies.computeIfPresent("A", (k, v) -> "Iron Man");
-
compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction)- 제공된 Key로 새 값을 계산하고 맵에 저장
- Key가 존재하면 새로운 값을 계산해 해당 Key와 매핑
- Key가 존재하지 않으면 새로운 Key와 값을 맵에 추가
favoriteMovies.compute("D", (k, v) -> "Joker");
삭제 패턴
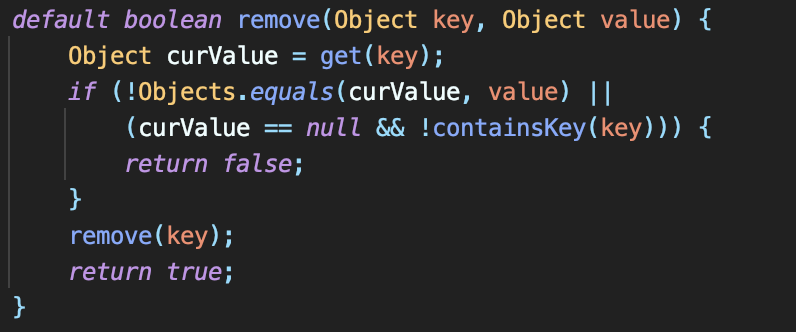
Java 8은 Key가 특정한 값과 연관되었을 때만 항목을 제거하는 오버로드 버전 remove 메서드를 제공한다
기존 remove 메서드는 다음과 같이 구현했다
String key = "A";
String value = "Star Wars";
if (favoriteMovies.containsKey(key) && Object.equals(favoriteMovies.get(key), value) {
favoriteMovies.remove(key);
return true;
} else {
return false;
}
Java 8은 간단하게 remove(key, value)로 구현할 수 있다
교체 패턴
맵의 항목을 바꾸는데 사용할 수 있는 두 개의 메서드가 추가되었다
-
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function)- BiFunction을 적용한 결과로 각 항목의 값을 교체
- List의 replaceAll 메서드와 비슷한 동작을 수행
-
default V replace(K key, V value)- 키가 존재하면 맵의 값을 변경
- 특정 값으로 매핑되었을 때만 값을 교체하는 오버로드 버전도 존재
default boolean replace(K key, V oldValue, V newValue)
public class MapReplaceExample {
public static void main(String[] args) {
Map<String, String> favoriteMovies = new HashMap<>();
favoriteMovies.put("A", "Star Wars");
favoriteMovies.put("B", "Avengers");
favoriteMovies.forEach((k, v) -> System.out.println("name = " + k + ", movie = " + v));
System.out.println();
// value 모두 대문자로 변경
favoriteMovies.replaceAll((k, v) -> v.toUpperCase());
favoriteMovies.forEach((k, v) -> System.out.println("name = " + k + ", movie = " + v));
System.out.println();
// A 값을 교체
favoriteMovies.replace("A", "Dark Knight");
// B 값이 Avengers 이면 교체, 아니면 그대로
favoriteMovies.replace("B", "Avengers", "Iron Man");
favoriteMovies.forEach((k, v) -> System.out.println("name = " + k + ", movie = " + v));
}
}

merge 메서드: 합침
두 개의 맵에서 값을 합치거나 바꿔야 한다면 merge() 메서드를 이용해야 한다.
만약 두 개의 맵을 합친다고 가정할 때 putAll()을 사용하면 맵을 합칠 수 있었다
Map<String, String> family;
Map<String, String> friends;
Map<String, String> everyone = new HashMap<>(family);
everyone.putAll(friends); // friends의 모든 항목을 everyone으로 복사

중복된 키가 없으면 아무런 문제 없이 잘 합쳐지지만, 중복된 키가 존재하면 어떻게 될까?
putAll() 메서드를 사용하면 나중에 합쳐진 값이 해당 키에 저장된다. 만약 유연하게 키가 중복되면 두 값을 모두 저장하고 싶다면 어떻게 해야할까? merge() 메서드를 사용하면 된다
-
V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction)- BiFunction을 사용해 키가 중복되면 어떻게 합칠지 결정할 수 있다
Map<String, String> everyone = new HashMap<>(family);
friends.forEach((k, v) -> everyone.merge
(k, v, (movie1, movie2) -> movie1 + " & " + movie2)
);
System.out.println("everyone = " + everyone);
merge 메서드는 null과 관련된 복잡한 상황도 처리한다
- 지정된 키와 연관된 값이 없거나 null이면 merge 메서드는 키를 null이 아닌 값과 연결한다. 아니면 연결된 값을 주어진 매핑 함수의 결과값으로 대치하거나 결과가 null이면 해당 항목을 제거한다
📌 개선된 ConcurrentHashMap
ConcurrentHashMap 클래스는 동시성 친화적이며 최신 기술이 반영된 HashMap 버전이다.
ConcurrentHashMap은 내부 자료구조의 특정 부분만 lock을 걸어 동시 추가, 갱신 작업을 허용한다. 따라서 동기화된 Hashtable 버전에 비해 읽기, 쓰기 연산 성능이 월등하다
표준 HashMap은 비동기로 동작
리듀스와 검색
ConcurrentHashMap은 스트림과 비슷한 종류의 세 가지 새로운 연산을 지원한다
- forEach: 각 key-value 쌍에 주어진 액션을 실행
- reduce: 모든 key-value 쌍을 제공된 리듀스 함수를 이용해 결과로 합침
- search: null이 아닌 값을 반환할 때까지 각 key-value 쌍에 함수를 적용
다음처럼 키에 함수 받기, 값, Map.Entry, (key, value) 인수를 이용한 네 가지 연산 형태를 지원한다
- 키, 값으로 연산: forEach, reduce, search
- 키로 연산: forEachKey, reduceKeys, searchKeys
- 값으로 연산: forEachValue, reduceValues, searchValues
- Map.Entry 객체로 연산: forEachEntry, reduceEntries, searchEntries
위 연산은 내부 상태를 잠그지 않고 연산을 수행하니 제공한 함수는 계산이 진행되는 동안 가변 객체, 값, 순서 등에 의존하지 않아야 한다.
또 병렬성 기준값(threshold)을 지정해야 한다. 맵의 크기가 주어진 기준값보다 작으면 순차적으로 연산을 실행한다. 기준값을 1로 지정하면 공통 스레드 풀을 이용해 병렬성을 극대화한다. 또 Long.MAX_VALUE를 기준값으로 설정하면 한 개의 스레드로 연산을 실행한다. SW 아키텍처가 고급 수준의 자원 활용 최적화를 사용하고 있지 않다면 기준값 규칙을 따르는 것이 좋다
계수
ConcurrentHashMap은 맵의 매핑 개수를 반환하는 mappingCount 메서드를 제공한다
기존의 size 메서드 대신 새 코드에서는 int를 반환하는 mappingCount 메서드를 사용하는 것이 좋다. 그래야 매핑의 개수가 int 범위를 넘어서는 이후의 상황을 대처할 수 있기 때문이다
집합 뷰
ConcurrentHashMap은 집합 뷰로 반환하는 keySet 메서드를 제공한다. 맵을 바꾸면 집합도 바뀌고, 반대로 집합을 바꾸면 맵도 영향을 받는다.
newKeySet 이라는 메서드를 이용해 ConcurrentHashMap으로 유지되는 집합을 만들 수도 있다
📌 Summary
- Java 9는 적은 원소를 포함하며 바꿀 수 없는(Unmodifiable) 리스트, 집합, 맵을 쉽게 만들 수 있는 팩토리 메서드인 of()를 제공한다
- List.of()
- Set.of()
- Map.of()
- Map.ofEntries()
- List 인터페이스는 removeIf(), replaceAll(), sort() 세 가지 default method를 지원
- Set 인터페이스는 removeIf() default method를 지원
- Map 인터페이스는 자주 사용하는 패턴과 버그를 방지할 수 있도록 다양한 default method를 지원
- ConcurrentHashMap은 Map 에서 상속받은 새 default method를 지원함과 동시에 스레드 안전성도 제공
댓글남기기